Pengukuran Web
Tools-tools pengukur analisis web :
SEO (Search Engine Optimization)
adalah mengoptimalkan sebuah blog/web dengan memanfaatkan mesin pencari dan mendapatkan peringkat yang tinggi di halaman pertama mesin pencari dengan menggunakan keyword agar dibanjiri pengunjung yang datang dari search engine.
GTmetrix
merupakan sebuah situs dimana kita dapat mengetahui berbagai hal yang membuat blog/web kita lambat dan performa blog/web ketika akses, tersedia secara gratis dengan mengunakan yahoo Yslow dan Google page speed sebagai mesin penganalisa dan menampilkan hasil juga rekomendasi yang harus dilakukan.
Kelebihan dari GTmetrix :
dapat membandingkan beberapa URL secara bersamaan
dapat menjadwalkan pengecekan web/blog secara otomatis dan dapat menyimpan laporan
Kekurangan dari GTmetrix:
dalam penggunaan GTmetrix harus menggunakan koneksi internet yang cepat.
Crawlers
Adalah proses pengambilan sejumlah besar halaman web dengan cepat kedalam satu tempat penyimpanan lokal dan mengindexnya berdasarkan sejumlah kata kunci. yakni sebuah komponen utama dalam sebuah Search Engine (Mesin Pencari), sebagai Aplikasi Information Retrieval Modern.
Cara kerja: suatu data dikumpulkan oleh web crawler kemudian digunakan oleh mesin pencari untuk memberikan link situs yang relavan bagi pengguna ketika mereka melakukan pencarian. web crawler menangkap banyak hal yang berbeda ketika mereka memindai situs. Informasi diperoleh dari metatag, konten itu sendiri dan link. untuk mendapatkan ide yang baik dari apa situs adalah tentang. Crawler digunakan sebagai scan situs anda. jika ada bagian-bagian tertentu dari situs yang seharusnya tidak diindeks, mereka harus mencatat dalam file ini. setelah mendapat instruksi crawler dari file ini, akan mulai dengan merangkak halaman situs anda.
Ini kemudian akan melanjutkan ke indeks konten, dan kemudian akhirnya akan mengunjungi link di situs Anda. Jika crawler mengikuti link dan tidak menemukan halaman, maka akan dihapus dari indeks. Informasi yang dikumpulkan dari situs Anda kemudian disimpan dalam database, yang kemudian digunakan oleh mesin pencari.
Beberapa Contoh Web Crawler :
Teleport Pro
Salah satu software web crawler untuk keperluan offline browsing. Software ini sudah cukup lama popular, terutama pada saat koneksi internet tidak semudah dan secepat sekarang. Software ini berbayar dan beralamatkan di http://www.tenmax.com.
HTTrack
Ditulis dengan menggunakan C, seperti juga Teleport Pro, HTTrack merupakan software yang dapat mendownload konten website menjadi sebuah mirror pada harddisk anda, agar dapat dilihat secara offline. Yang menarik software ini free dan dapat di download pada website resminya di http://www.httrack.com
Googlebot
Merupakan web crawler untuk membangun index pencarian yang digunakan oleh search engine Google. Kalau website anda ditemukan orang melalui Google, bisa jadi itu merupakan jasa dari Googlebot. Walau konsekuensinya, sebagian bandwidth anda akan tersita karena proses crawling ini.
Yahoo!Slurp
Kalau Googlebot adalah web crawler andalan Google, maka search engine Yahoo mengandalkan Yahoo!Slurp. Teknologinya dikembangkan oleh Inktomi Corporation yang diakuisisi oleh Yahoo!.
YaCy
Sedikit berbeda dengan web crawler lainnya di atas, YaCy dibangun atas prinsip jaringan P2P (peer-to-peer), di develop dengan menggunakan java, dan didistribusikan pada beberapa ratus mesin computer (disebut YaCy peers). Tiap-tiap peer di share dengan prinsip P2P untuk berbagi index, sehingga tidak memerlukan server central. Contoh search engine yang menggunakan YaCy ialah Sciencenet, untuk pencarian dokumen di bidang sains.
Search Engines
Adalah program komputer yang dirancang untuk melakukan pencarian atas berkas-berkas yang tersimpan dalam layanan www, ftp, publikasi milis, ataupun news group dalam sebuah ataupun sejumlah komputer peladen dalam suatu jaringan. Search engine merupakan perangkat pencari informasi dari dokumen-dokumen yang tersedia. Hasil pencarian umumnya ditampilkan dalam bentuk daftar yang seringkali diurutkan menurut tingkat akurasi ataupun rasio pengunjung atas suatu berkas yang disebut sebagai hits. Informasi yang menjadi target pencarian bisa terdapat dalam berbagai macam jenis berkas seperti halaman situs web, gambar, ataupun jenis-jenis berkas lainnya. Beberapa mesin pencari juga diketahui melakukan pengumpulan informasi atas data yang tersimpan dalam suatu basisdata ataupun direktori web.
Sebagian besar mesin pencari dijalankan oleh perusahaan swasta yang menggunakan algoritma kepemilikan dan basisdata tertutup, di antaranya yang paling populer adalah Google (MSN Search dan Yahoo!). Telah ada beberapa upaya menciptakan mesin pencari dengan sumber terbuka (open source), contohnya adalah Htdig, Nutch, Egothor dan OpenFTS.
Contoh-contoh search engine :
Google
google muncul pada akhir tahun 1997, dimana google memasuki pasar yang telah diisi oleh para pesaing lain dalam penyediaan layanan mesin pencari, seperti Yahoo, Altavista , HotBot, Excite, InfoSeek dan Lycos. dimana perusahaan-perusahaan tersebut mengklaim sebagain perusahaan tabg bergerak dalam bidang layanan pencarian internert. Hingga akhirnya Google mampu menjadi sebagai penyedia mesin pencari yang cukup diperhitungkan didunia.
Yahoo
Yahoo raja directori di internet disamping para pengguna internet melihat DMOZ serta LookSma berusaha menurunkan nya diposisi puncak tersebut. akhir-akhir ini telah tumbuh secara cepat dalam ukurannya mereka pun sudah memliki harga sehingga mudah untuk memasukinya, dengan demikian mendapatkan sebuah daftar pada direktori yahoo memang memiliki nilai yang tinggi.
Web Archiving
adalah proses mengumpulkan bagian dari WWW dan memastikan koleksi tersebut diawetkan dalam suatu arsip, misalnya situs arsip, untuk diakses peneliti, sejarawan, dan masyarakat umum pada masa datang. Besarnya ukuran Web membuat arsiparis web umumnya menggunakan web crawlers untuk pengumpulan secara otomatis. Organisasi pengarsip web terbesar yang menggunakan ancangan perangkak web ini adalah Internet Archive yang berupaya memelihara arsip dari seluruh Web. Perpustakaan nasional, arsip nasional, dan berbagai konsorsium organisasi lain juga terlibat dalam upaya pengarsipan konten Web yang memiliki nilai penting bagi mereka. Perangkat lunak dan layanan komersial juga tersedia bagi organisasi yang ingin mengarsipkan konten web mereka sendiri untuk berbagai keperluan.
Cara kerja web archiving
Remote Harvesting
Merupakan cara yang plaing umum dalam web archiving dengan menggunkana teknik web crawlers yang secara otomatis melakukan proses pengumpulan halaman web. Metode yang digunakan web crawler untuk mengakses halaman web sama semeprti user mengakses halaman web menggunakan wob browser. Contoh web crawler yang digunakan dalam web archiving seperti :
Heritrix, HTTrack, Wget
On-Demand
Ada banyak layanan yang dapat digunakan sebagai sumber archive web "on-demand", menggunakan teknik web crawling. Contohnya seperti:
Aleph Archives, archive.is, Archive-It, Archivethe.net, Compliance WatchDog by SiteQuest Technologies, freezePAGE snapshots, Hanzo Archives, Iterasi, Nextpoint, Patrina, PageFreezer, Reed Archives, Smarsh Web Archiving, The Web Archiving Service, webEchoFS, WebCite, Website-Archive.com
Database archiving
Databasa Archiving mengacu pada metode untuk menarsipkan konten database-driven websites. Hal ini biasanya memerlukan ekstraksi konten database ke standard schema, sering menggunakan XML. Setelah disimpan dalam format standar, konten yang diarsipkan dari beberapa databse dapat tersedia untuk diakses dengan menggunakan single access system. Motode ini digunkanan seprti pada DeepArc dan Xinq masiing masing dikembangkan oleh Bibliothèque nationale de France dan National Library of Australia.
Transactional archiving
Transactional archiving merupakan event-driven yang mengumpulkan transaksi yang berlangsung antara web server dan web browser. Hal ini terutama digunakan untuk menjamin keaslian dari isi suatu website, pada tanggal tertentu. Hal ini sangatlah penting untuk organisasi atau perusahaan yang perlu mematuhi persyaratan hukum atau peraturan untuk mengungkapkan dan mempertahankan informasi.
Sistem yang digunakan pada transactional archiving biasanya beroperasi dengan memeriksa setiap permintaan HTTP dan respon dari web server, menyaring setiap aktifitas untuk menghilangkan konten yang duklikat dan secara permanen disimpan sebagai bitstreams. Sebuah sistem transactional archiving membutuhkan instalasi perangkat lunak pada web server, dan karena hal itu maka metode ini tidka dapat mengumpulkan konten dari remote website.
Sumber : http://vkarlina.blogspot.com/2014/06/analisis-web.html
Jumat, 04 Juli 2014
Struktur web
Link Structure dan Small World
Sebuah jaringan kecil dunia adalah jenis grafik matematika di mana sebagian besar node tidak tetangga satu sama lain, tetapi kebanyakan node dapat dicapai dari setiap lain oleh sejumlah kecil hop atau langkah-langkah. Secara khusus, jaringan-dunia kecil didefinisikan sebagai jaringan di mana L jarak khas antara dua node yang dipilih secara acak (jumlah langkah yang diperlukan) tumbuh secara proporsional dengan logaritma dari jumlah node N dalam jaringan, yaitu:
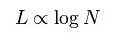
Dalam konteks jaringan sosial, hasil ini dalam fenomena dunia kecil dari orang asing yang dihubungkan oleh saling kenalan. Banyak grafik empiris dengan baik dimodelkan oleh jaringan kecil dunia. Jaringan sosial , konektivitas dari internet , wiki seperti Wikipedia, dan jaringan gen semua karakteristik jaringan-dunia kecil pameran.
Social Network Sites
Social Network sites adalah sebutan lain terhadap website community. Social Network sites adalah tempat untuk para netter berkolaborasi dengan netter lainnya. Bentuk kolaborasi antara lain adalah saling bertukar pendapat/komentar, mencari teman, saling mengirim email, saling memberi penilaian, saling bertukar file dan yang lainnya. Intinya dari situs social networking adalah interaktifitas. Contoh dari social network sites yang sering digunakan: Facebook, Friendster, MySpace, Twitter, dll.
Blogosphere
Blogosphere adalah suatu interkoneksi / interaksi antar blog yangg tergabung dalam sebuah domain dan domain tersebut tergabung dalam lingkup jaringan / internet, Contohnya, Technorati, Top of Blogs, Blog Top site, blogspot termasuk juga dengan blog directory, sebuah blogosphere biasanya diklasifikasikan menurut jenis postingan, ada berupa blog berita, blog hoby , blog forum, blog komunitas, blog iformasi dll.Istilah Blogosphere muncul pada tahun 1999 dan mulai populer tahun 2002, walaupun lahir dari sebuah lelucon keberadaan Blogosphere kini menjadi sebuah ikon bagi blogger, banyak blogger yang menganggap belum lengkap bila seorang blogger belum tergabung ke dalam komunitas Blogosphere hingga jadi ikon eksistensinya dalam dunia blogging.
Manfaat Blogosphere ini tak lepas kaitannya dari SEO ( Search Engine Optimization ), layaknya sebuah komunitas keberadaan Blogosphere memberikan jalinan komunikasi antar blogger, membuat akses posting yg popular dan menjadi sebuah trend, atau mengupdate suatu bahasa dan kosakata untuk sebuah komunitas blog sehingga menjadi kepopuleran tersendiri.
Sumber : http://vkarlina.blogspot.com/2014/06/struktur-web.html
Sebuah jaringan kecil dunia adalah jenis grafik matematika di mana sebagian besar node tidak tetangga satu sama lain, tetapi kebanyakan node dapat dicapai dari setiap lain oleh sejumlah kecil hop atau langkah-langkah. Secara khusus, jaringan-dunia kecil didefinisikan sebagai jaringan di mana L jarak khas antara dua node yang dipilih secara acak (jumlah langkah yang diperlukan) tumbuh secara proporsional dengan logaritma dari jumlah node N dalam jaringan, yaitu:
Dalam konteks jaringan sosial, hasil ini dalam fenomena dunia kecil dari orang asing yang dihubungkan oleh saling kenalan. Banyak grafik empiris dengan baik dimodelkan oleh jaringan kecil dunia. Jaringan sosial , konektivitas dari internet , wiki seperti Wikipedia, dan jaringan gen semua karakteristik jaringan-dunia kecil pameran.
Social Network Sites
Social Network sites adalah sebutan lain terhadap website community. Social Network sites adalah tempat untuk para netter berkolaborasi dengan netter lainnya. Bentuk kolaborasi antara lain adalah saling bertukar pendapat/komentar, mencari teman, saling mengirim email, saling memberi penilaian, saling bertukar file dan yang lainnya. Intinya dari situs social networking adalah interaktifitas. Contoh dari social network sites yang sering digunakan: Facebook, Friendster, MySpace, Twitter, dll.
Blogosphere
Blogosphere adalah suatu interkoneksi / interaksi antar blog yangg tergabung dalam sebuah domain dan domain tersebut tergabung dalam lingkup jaringan / internet, Contohnya, Technorati, Top of Blogs, Blog Top site, blogspot termasuk juga dengan blog directory, sebuah blogosphere biasanya diklasifikasikan menurut jenis postingan, ada berupa blog berita, blog hoby , blog forum, blog komunitas, blog iformasi dll.Istilah Blogosphere muncul pada tahun 1999 dan mulai populer tahun 2002, walaupun lahir dari sebuah lelucon keberadaan Blogosphere kini menjadi sebuah ikon bagi blogger, banyak blogger yang menganggap belum lengkap bila seorang blogger belum tergabung ke dalam komunitas Blogosphere hingga jadi ikon eksistensinya dalam dunia blogging.
Manfaat Blogosphere ini tak lepas kaitannya dari SEO ( Search Engine Optimization ), layaknya sebuah komunitas keberadaan Blogosphere memberikan jalinan komunikasi antar blogger, membuat akses posting yg popular dan menjadi sebuah trend, atau mengupdate suatu bahasa dan kosakata untuk sebuah komunitas blog sehingga menjadi kepopuleran tersendiri.
Sumber : http://vkarlina.blogspot.com/2014/06/struktur-web.html
Langganan:
Postingan (Atom)